Today, AWS announced Ubuntu support for Finch, an open source command line tool that allows developers to build, run, and publish Linux containers. Finch simplifies container development by bundling a minimal native client with a curated selection of open-source components.
With the addition of Ubuntu support, Finch now provides a consistent and streamlined container development experience across more Linux distributions, addressing a key pain point for developers who work across multiple environments. Previously, Ubuntu users needed to build Finch from source and handle dependency management, which required additional setup time and coordination across development teams. Now, they can easily install Finch using Ubuntu’s APT package manager. This expansion allows teams to standardize their container workflows and tooling, improving productivity and collaboration across different Linux flavors.
Finch’s Ubuntu support is available in the deb file format for Ubuntu LTS versions. Detailed installation instructions and troubleshooting guides are now available on the project’s website and GitHub repository, ensuring a smoother setup process for users across different Linux distributions. To learn more about using Finch on Linux, read the AWS News Blog.
Today, AWS announced Ubuntu support for Finch, an open source command line tool that allows developers to build, run, and publish Linux containers. Finch simplifies container development by bundling a minimal native client with a curated selection of open-source components. With the addition of Ubuntu support, Finch now provides a consistent and streamlined container development experience across more Linux distributions, addressing a key pain point for developers who work across multiple environments. Previously, Ubuntu users needed to build Finch from source and handle dependency management, which required additional setup time and coordination across development teams. Now, they can easily install Finch using Ubuntu’s APT package manager. This expansion allows teams to standardize their container workflows and tooling, improving productivity and collaboration across different Linux flavors. Finch’s Ubuntu support is available in the deb file format for Ubuntu LTS versions. Detailed installation instructions and troubleshooting guides are now available on the project’s website and GitHub repository, ensuring a smoother setup process for users across different Linux distributions. To learn more about using Finch on Linux, read the AWS News Blog.
Today, AWS Config rules adds classification information from AWS Control Tower Control Catalog to make it easier for you to identify how Config rules map to different compliance frameworks such as CIS-v8.0, FedRAMP-r4, and NIST-CSF-v1.1. AWS Config rules help you automatically evaluate your AWS resource configurations for desired settings, enabling you to assess, audit, and evaluate configurations of your AWS resources. Control Catalog is a feature of AWS Control Tower that enables you to search AWS managed controls and their associated compliance frameworks.
Control Catalog has classifications including Domain (such as «Data Protection»), Objective (such as «Data Encryption»), and common control (such as «Encrypt data at rest») to help you better understand the purpose of a control. Today’s launch maps AWS Config rules to the specific compliance frameworks available in AWS Control Tower Control Catalog (CIS-v8.0, FedRAMP-r4, ISO-IEC-27001:2013-Annex-A, NIST-CSF-v1.1, NIST-SP-800-171-r2, PCI-DSS-v4.0, SSAE-18-SOC-2-Oct-2023), adding classification information (Domain, Objective, common control) to each AWS Config rule.
If you’re using AWS Config, you’ll now see the same classification information in the AWS Config Console and in the AWS Control Tower Control Catalog, ensuring a unified experience across your AWS environment. This alignment between AWS Control Tower and AWS Config allows for seamless integration and more efficient management of your compliance and security posture.
AWS Config rules with classifications from AWS Control Tower Control Catalog are available in all AWS Commercial regions where AWS Config and AWS Control Tower are available.
To learn more about AWS Config rules and compliance frameworks, visit the AWS Config documentation.
Today, AWS Config rules adds classification information from AWS Control Tower Control Catalog to make it easier for you to identify how Config rules map to different compliance frameworks such as CIS-v8.0, FedRAMP-r4, and NIST-CSF-v1.1. AWS Config rules help you automatically evaluate your AWS resource configurations for desired settings, enabling you to assess, audit, and evaluate configurations of your AWS resources. Control Catalog is a feature of AWS Control Tower that enables you to search AWS managed controls and their associated compliance frameworks. Control Catalog has classifications including Domain (such as «Data Protection»), Objective (such as «Data Encryption»), and common control (such as «Encrypt data at rest») to help you better understand the purpose of a control. Today’s launch maps AWS Config rules to the specific compliance frameworks available in AWS Control Tower Control Catalog (CIS-v8.0, FedRAMP-r4, ISO-IEC-27001:2013-Annex-A, NIST-CSF-v1.1, NIST-SP-800-171-r2, PCI-DSS-v4.0, SSAE-18-SOC-2-Oct-2023), adding classification information (Domain, Objective, common control) to each AWS Config rule. If you’re using AWS Config, you’ll now see the same classification information in the AWS Config Console and in the AWS Control Tower Control Catalog, ensuring a unified experience across your AWS environment. This alignment between AWS Control Tower and AWS Config allows for seamless integration and more efficient management of your compliance and security posture. AWS Config rules with classifications from AWS Control Tower Control Catalog are available in all AWS Commercial regions where AWS Config and AWS Control Tower are available. To learn more about AWS Config rules and compliance frameworks, visit the AWS Config documentation.
You can now use Amazon EBS General Purpose SSD volumes (gp3) volumes with the second-generation AWS Outposts racks for your workloads that require local data processing and data residency. The latest generation of gp3 enables you to provision performance independently of storage capacity, delivering a baseline performance of 3,000 IOPS and 125 MB/s at any volume size. With gp3 volumes, you can scale up to 16,000 IOPS and 1,000 MB/s, delivering 4x the maximum throughput of the previously supported gp2 volumes.
EBS gp3 volumes on second-generation AWS Outposts are ideal for a wide variety of performance-intensive applications, including MySQL, Cassandra, virtual desktops, and Hadoop analytics clusters. AWS Outposts racks offer the same AWS infrastructure, AWS services, APIs, and tools to virtually any on-premises data center or colocation space for a truly consistent hybrid experience. Second-generation AWS Outposts racks support the latest generation of x86-powered Amazon Elastic Compute Cloud (Amazon EC2) instances, starting with C7i, M7i, and R7i instances. These instances deliver twice the vCPU, memory, and network bandwidth, as well as up to 40% better performance compared to C5, M5, and R5 instances on first-generation AWS Outposts racks.
You can manage gp3 volumes using the AWS Management Console, the AWS Command Line Interface (CLI), or the AWS SDKs in all Regions and countries/territories where second-generationAWS Outposts racks are supported. For more information on gp3 volumes, see the product overview page. For a current list of AWS Regions and countries/territories where second-generation AWS Outposts racks are supported, check out the AWS Outposts racks FAQs page.
You can now use Amazon EBS General Purpose SSD volumes (gp3) volumes with the second-generation AWS Outposts racks for your workloads that require local data processing and data residency. The latest generation of gp3 enables you to provision performance independently of storage capacity, delivering a baseline performance of 3,000 IOPS and 125 MB/s at any volume size. With gp3 volumes, you can scale up to 16,000 IOPS and 1,000 MB/s, delivering 4x the maximum throughput of the previously supported gp2 volumes. EBS gp3 volumes on second-generation AWS Outposts are ideal for a wide variety of performance-intensive applications, including MySQL, Cassandra, virtual desktops, and Hadoop analytics clusters. AWS Outposts racks offer the same AWS infrastructure, AWS services, APIs, and tools to virtually any on-premises data center or colocation space for a truly consistent hybrid experience. Second-generation AWS Outposts racks support the latest generation of x86-powered Amazon Elastic Compute Cloud (Amazon EC2) instances, starting with C7i, M7i, and R7i instances. These instances deliver twice the vCPU, memory, and network bandwidth, as well as up to 40% better performance compared to C5, M5, and R5 instances on first-generation AWS Outposts racks. You can manage gp3 volumes using the AWS Management Console, the AWS Command Line Interface (CLI), or the AWS SDKs in all Regions and countries/territories where second-generation AWS Outposts racks are supported. For more information on gp3 volumes, see the product overview page. For a current list of AWS Regions and countries/territories where second-generation AWS Outposts racks are supported, check out the AWS Outposts racks FAQs page.
Amazon Elastic Container Services (Amazon ECS) now makes it easier to troubleshoot unhealthy tasks by adding the Task ID in service action events generated due to health failures.
Amazon ECS is designed to help easily launch and scale your applications. When your Amazon ECS task fails Elastic Load Balancing (ELB) health checks, Amazon ECS produces an unhealthy service action event. With today’s launch, the Task ID is also included as part of the generated event, so you can quickly pinpoint the Task in question for faster troubleshooting.
Amazon Elastic Container Services (Amazon ECS) now makes it easier to troubleshoot unhealthy tasks by adding the Task ID in service action events generated due to health failures. Amazon ECS is designed to help easily launch and scale your applications. When your Amazon ECS task fails Elastic Load Balancing (ELB) health checks, Amazon ECS produces an unhealthy service action event. With today’s launch, the Task ID is also included as part of the generated event, so you can quickly pinpoint the Task in question for faster troubleshooting. The new experience is now automatically enabled in all AWS Regions. See more details regarding unhealthy Service Events in the Amazon ECS documentation and how to set up Amazon EventBridge rules to capture Amazon ECS service action events.
We are excited to announce that Amazon Athena is now available in Asia Pacific (Taipei).
Athena is a serverless, interactive query service that makes it simple to analyze petabytes of data using SQL, without requiring infrastructure setup or management. Athena is built on open-source Trino and Presto query engines, providing powerful and flexible interactive query capabilities, and supports popular data formats such as Apache Parquet and Apache Iceberg.
For more information about the AWS Regions where Athena is available, see the AWS Region table. To learn more, see Amazon Athena.
We are excited to announce that Amazon Athena is now available in Asia Pacific (Taipei). Athena is a serverless, interactive query service that makes it simple to analyze petabytes of data using SQL, without requiring infrastructure setup or management. Athena is built on open-source Trino and Presto query engines, providing powerful and flexible interactive query capabilities, and supports popular data formats such as Apache Parquet and Apache Iceberg. For more information about the AWS Regions where Athena is available, see the AWS Region table. To learn more, see Amazon Athena.
Amazon Textract is a managed machine learning service that automatically extracts text, handwriting, and data from any document or image. We regularly improve the underlying machine learning models based on customer feedback to provide even better accuracy. Today, we are pleased to announce feature and accuracy updates to the text detection model used in Textract DetectDocumentText and AnalyzeDocument APIs.
This update adds support for superscripts, subscripts, and rotated text in documents. The update also includes accuracy improvements for text detection in box forms, extraction of visually similar character sets (e.g., ‘0’ vs. ‘O’), and lower-resolution documents such as faxes.
This update is now available in US East (Ohio, N. Virginia), US West (N. California, Oregon), Asia Pacific (Mumbai, Seoul, Singapore, Sydney), Canada (Central), Europe (Frankfurt, Ireland, London, Paris, Spain), and AWS GovCloud (US-East, US-West) Regions.
Amazon Textract is a managed machine learning service that automatically extracts text, handwriting, and data from any document or image. We regularly improve the underlying machine learning models based on customer feedback to provide even better accuracy. Today, we are pleased to announce feature and accuracy updates to the text detection model used in Textract DetectDocumentText and AnalyzeDocument APIs. This update adds support for superscripts, subscripts, and rotated text in documents. The update also includes accuracy improvements for text detection in box forms, extraction of visually similar character sets (e.g., ‘0’ vs. ‘O’), and lower-resolution documents such as faxes. This update is now available in US East (Ohio, N. Virginia), US West (N. California, Oregon), Asia Pacific (Mumbai, Seoul, Singapore, Sydney), Canada (Central), Europe (Frankfurt, Ireland, London, Paris, Spain), and AWS GovCloud (US-East, US-West) Regions. To get started, log on to the Amazon Textract console. To learn more about Textract capabilities, please visit the Amazon Textract website, developer guide, or resources page.
Amazon Connect can now integrate agent activities from third-party applications as Connect Tasks, which can be evaluated alongside work completed in Connect, providing managers with a unified application for quality management. You can programmatically ingest activities from third-party applications (such as application processing, social media posts, etc.) as completed Tasks within Connect, capturing details relevant for performance evaluation as Task attributes. Managers can then evaluate these external activities, alongside native Connect interactions to get a unified view of agent performance within Connect dashboards.
This feature is available in all regions where Contact Lens performance evaluations are already available. To learn more, please visit our documentation and our webpage. For information about Contact Lens pricing, please visit our pricing page.
Amazon Connect can now integrate agent activities from third-party applications as Connect Tasks, which can be evaluated alongside work completed in Connect, providing managers with a unified application for quality management. You can programmatically ingest activities from third-party applications (such as application processing, social media posts, etc.) as completed Tasks within Connect, capturing details relevant for performance evaluation as Task attributes. Managers can then evaluate these external activities, alongside native Connect interactions to get a unified view of agent performance within Connect dashboards. This feature is available in all regions where Contact Lens performance evaluations are already available. To learn more, please visit our documentation and our webpage. For information about Contact Lens pricing, please visit our pricing page.
Amazon Simple Email Service (Amazon SES) is now available in the Asia Pacific (Hyderabad), Middle East (UAE), and Europe (Zurich) Regions. Customers can now use these new Regions to leverage Amazon SES to send emails and, if needed, to help manage data sovereignty requirements.
Amazon SES is a scalable, cost-effective, and flexible cloud-based email service that allows digital marketers and application developers to send marketing, notification, and transactional emails from within any application. To learn more about Amazon SES, visit this page.
With this launch, Amazon SES is available in 27 AWS Regions globally: US East (Virginia, Ohio), US West (N. California, Oregon), AWS GovCloud (US-West, US-East), Asia Pacific (Osaka, Mumbai, Hyderabad, Sydney, Singapore, Seoul, Tokyo, Jakarta), Canada (Central), Europe (Ireland, Frankfurt, London, Paris, Stockholm, Milan, Zurich), Israel (Tel Aviv), Middle East (Bahrain, UAE), South America (São Paulo), and Africa (Cape Town).
For a complete list of all of the regional endpoints for Amazon SES, see AWS Service Endpoints in the AWS General Reference.
Amazon Simple Email Service (Amazon SES) is now available in the Asia Pacific (Hyderabad), Middle East (UAE), and Europe (Zurich) Regions. Customers can now use these new Regions to leverage Amazon SES to send emails and, if needed, to help manage data sovereignty requirements. Amazon SES is a scalable, cost-effective, and flexible cloud-based email service that allows digital marketers and application developers to send marketing, notification, and transactional emails from within any application. To learn more about Amazon SES, visit this page. With this launch, Amazon SES is available in 27 AWS Regions globally: US East (Virginia, Ohio), US West (N. California, Oregon), AWS GovCloud (US-West, US-East), Asia Pacific (Osaka, Mumbai, Hyderabad, Sydney, Singapore, Seoul, Tokyo, Jakarta), Canada (Central), Europe (Ireland, Frankfurt, London, Paris, Stockholm, Milan, Zurich), Israel (Tel Aviv), Middle East (Bahrain, UAE), South America (São Paulo), and Africa (Cape Town). For a complete list of all of the regional endpoints for Amazon SES, see AWS Service Endpoints in the AWS General Reference.
Zonal autoshift practice runs take place once a week to ensure your application is ready for a zonal shift. Now with on-demand practice runs, you can trigger a practice run anytime you want to and validate your application’s preparedness. When a practice run is started, a pre-check will be performed to ensure your application has balanced capacity across AZs. This check is done for Application Load Balancers, Network Load Balancers, and EC2 Auto Scaling groups.
To get started, you can initiate an on-demand practice run in the ARC console, API, or CLI. This allows you to test your application’s practice run configuration to ensure the alarms are configured correctly and your application behaves as expected. For both automated and on-demand practice, pre-checks for balanced capacity will validate your resource’s capacity and ensure it’s safe to start the practice. If the pre-check fails, you’ll be alerted, so you can take corrective action.
Zonal autoshift practice runs take place once a week to ensure your application is ready for a zonal shift. Now with on-demand practice runs, you can trigger a practice run anytime you want to and validate your application’s preparedness. When a practice run is started, a pre-check will be performed to ensure your application has balanced capacity across AZs. This check is done for Application Load Balancers, Network Load Balancers, and EC2 Auto Scaling groups. To get started, you can initiate an on-demand practice run in the ARC console, API, or CLI. This allows you to test your application’s practice run configuration to ensure the alarms are configured correctly and your application behaves as expected. For both automated and on-demand practice, pre-checks for balanced capacity will validate your resource’s capacity and ensure it’s safe to start the practice. If the pre-check fails, you’ll be alerted, so you can take corrective action. Zonal autoshift on-demand practice runs and practice run pre-checks for balanced capacity are available in all commercial AWS Regions, and including AWS GovCloud (US) Regions. To learn more, please refer to the ARC zonal autoshift documentation.
El equipo de IA de Microsoft comparte investigaciones que demuestran cómo la IA puede investigar y resolver de manera secuencial, los desafíos de diagnóstico más complejos de la medicina, casos que los médicos expertos luchan por responder.
Comparados con los registros de casos del mundo real publicados cada semana en el New England Journal of Medicine, mostramos que el Microsoft AI Diagnostic Orchestrator (MAI-DxO) diagnostica de manera correcta hasta el 85% de los procedimientos de casos de NEJM, una tasa más de cuatro veces superior a la de un grupo de médicos experimentados. MAI-DxO también llega al diagnóstico correcto de manera más rentable que los médicos.
—
A medida que la demanda de atención médica continúa su crecimiento, los costos aumentan a un ritmo insostenible y miles de millones de personas enfrentan múltiples barreras para una mejor salud, incluidos diagnósticos inexactos y tardíos. Cada vez más, las personas recurren a las herramientas digitales para obtener asesoramiento y apoyo médico. En los productos de consumo de IA de Microsoft, como Bing y Copilot, vemos más de 50 millones de sesiones relacionadas con la salud todos los días. Desde una consulta por primera vez sobre el dolor de rodilla hasta una búsqueda nocturna de una clínica de atención urgente, los motores de búsqueda y los compañeros de IA se convierten con rapidez en la nueva primera línea de la atención médica.
Queremos hacer más para ayudar, y creemos que la IA generativa puede ser transformadora. Por eso, a finales de 2024, lanzamos un esfuerzo dedicado a la salud del consumidor en Microsoft AI, dirigido por médicos, diseñadores, ingenieros y científicos de IA. Este esfuerzo complementa las iniciativas de salud más amplias de Microsoft y se basa en nuestro compromiso de larga data con la asociación y la innovación. Las soluciones existentes incluyen RAD-DINO, que ayuda a acelerar y mejorar los flujos de trabajo de radiología, y Microsoft Dragon Copilot, nuestro asistente pionero de IA de voz para médicos.
Para que la IA marque la diferencia, tanto los médicos como los pacientes deben poder confiar en su rendimiento. Ahí es donde entran en juego nuestros nuevos puntos de referencia y el orquestador de IA.
Desafíos y puntos de referencia de casos médicos
Para ejercer la medicina en los Estados Unidos, los médicos deben aprobar el Examen de Licencia Médica de los Estados Unidos (USMLE, por sus siglas en inglés), una evaluación rigurosa y estandarizada del conocimiento clínico y la toma de decisiones. Las preguntas USMLE se encuentran entre los primeros puntos de referencia utilizados para evaluar los sistemas de IA en medicina, ya que ofrecen una forma estructurada de comparar el rendimiento de los modelos, tanto entre sí como con los clínicos humanos.
En solo tres años, la IA generativa ha avanzado hasta el punto de obtener puntuaciones casi perfectas en el USMLE y exámenes similares. Pero estas pruebas se basan en su mayoría en preguntas de opción múltiple, que favorecen la memorización sobre la comprensión profunda. Al reducir la medicina a respuestas únicas a preguntas de opción múltiple, estos puntos de referencia exageran la aparente competencia de los sistemas de IA y oscurecen sus limitaciones.
En Microsoft AI, trabajamos para avanzar y evaluar las capacidades de razonamiento clínico. Para ir más allá de las limitaciones de las preguntas de opción múltiple, nos hemos centrado en el diagnóstico secuencial, una piedra angular de la toma de decisiones médicas en el mundo real. En este proceso, un médico comienza con una presentación inicial para el paciente y luego selecciona de manera iterativa preguntas y pruebas diagnósticas para llegar a un diagnóstico final. Por ejemplo, un paciente que presenta tos y fiebre puede llevar al médico a ordenar y revisar análisis de sangre y una radiografía de tórax antes de sentirse seguro de diagnosticar neumonía.
Cada semana, el New England Journal of Medicine (NEJM), una de las revistas médicas más importantes del mundo, publica un registro de caso del Hospital General de Massachusetts, que presenta el proceso de atención de un paciente en un formato narrativo detallado. Estos casos se encuentran entre los más complejos diagnósticos y de una gran exigencia a nivel intelectual, de la medicina clínica, ya que a menudo requieren múltiples especialistas y pruebas diagnósticas para llegar a un diagnóstico definitivo.
¿Cómo se comporta la IA? Para responder a esto, creamos desafíos de casos interactivos extraídos de la serie de casos de NEJM, lo que llamamos el Punto de Referencia de Diagnóstico Secuencial (SD Bench). Este punto de referencia transforma 304 casos recientes de NEJM en encuentros de diagnóstico escalonados en los que los modelos, o los médicos humanos, pueden hacer preguntas y solicitar pruebas de forma iterativa. A medida que se dispone de nueva información, el modelo o el clínico actualizan su razonamiento, acercándose de manera gradual a un diagnóstico final. Este diagnóstico puede compararse con el resultado de referencia publicado en el NEJM.
Cada investigación solicitada también incurre en un costo (virtual), que refleja los gastos de atención médica del mundo real. Esto nos permite evaluar el rendimiento en dos dimensiones clave: la precisión del diagnóstico y el gasto de recursos. Pueden ver cómo un sistema de IA avanza a través de uno de estos desafíos en este breve video.
Tutorial de cómo MAI-DxO trabaja a través de un caso para llegar a un diagnóstico.
Cómo llegar a un diagnóstico correcto
Evaluamos un conjunto completo de modelos de IA generativa de frontera frente a los 304 casos de NEJM. Los modelos de base probados incluyeron GPT, Llama, Claude, Gemini, Grok y DeepSeek.
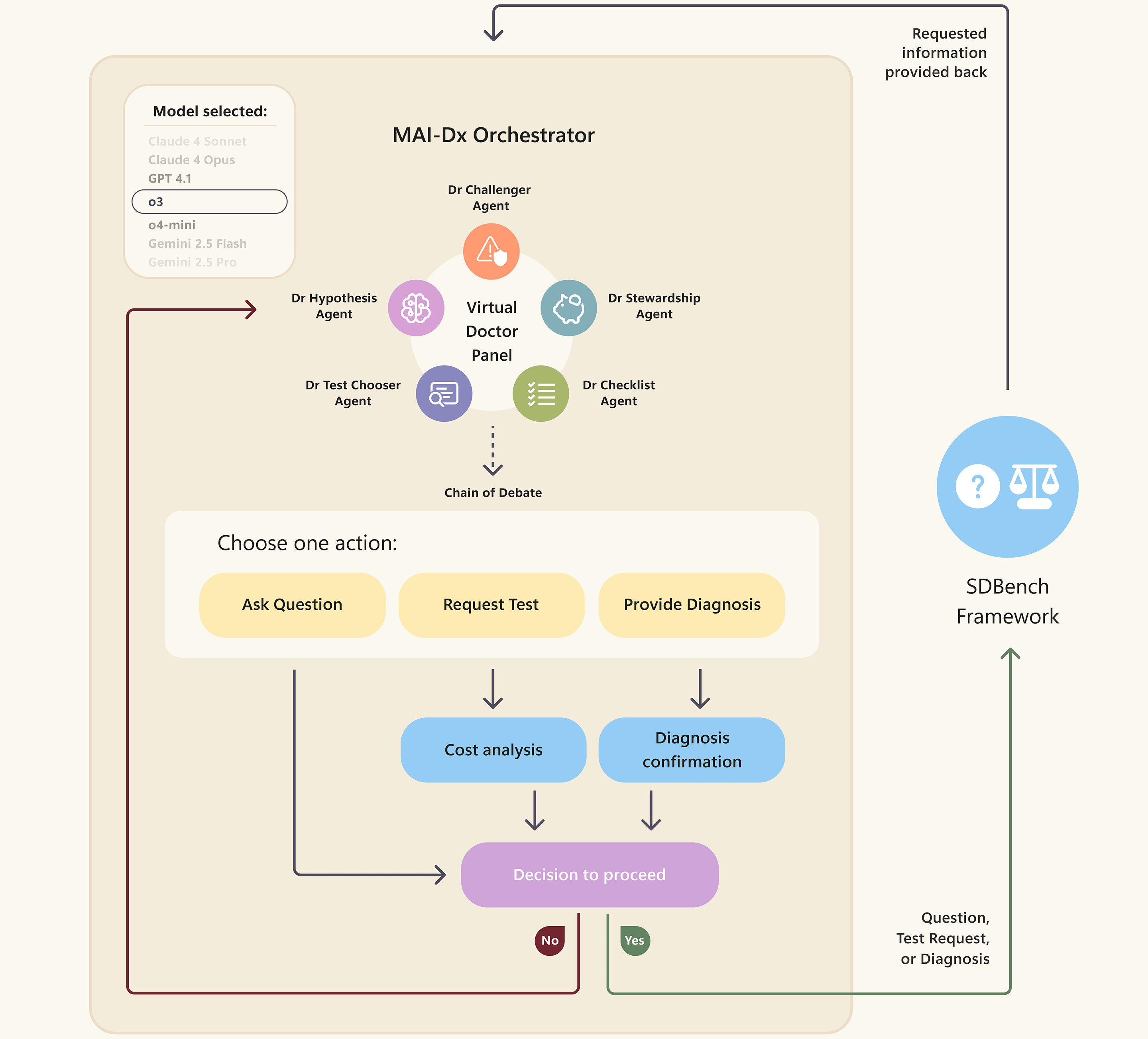
Más allá de la evaluación comparativa de referencia, también desarrollamos Microsoft AI Diagnostic Orchestrator (MAI-DxO), un sistema diseñado para emular un panel virtual de médicos con diversos enfoques de diagnóstico que colaboran para resolver casos de diagnóstico. Creemos que la orquestación de múltiples modelos de lenguaje será fundamental para gestionar flujos de trabajo clínicos complejos. Los orquestadores pueden integrar diversas fuentes de datos de forma más eficaz que los modelos individuales, al tiempo que mejoran la seguridad, la transparencia y la adaptabilidad en respuesta a las necesidades médicas cambiantes. Este enfoque independiente del modelo promueve la auditabilidad y la resiliencia, atributos clave en entornos clínicos de alto riesgo y rápida evolución.
El MAI-Dx Orchestrator convierte cualquier modelo de lenguaje en un panel virtual de médicos: puede hacer preguntas de seguimiento, solicitar pruebas o entregar un diagnóstico, luego ejecutar una verificación de costos y verificar su propio razonamiento antes de decidir si continuar.
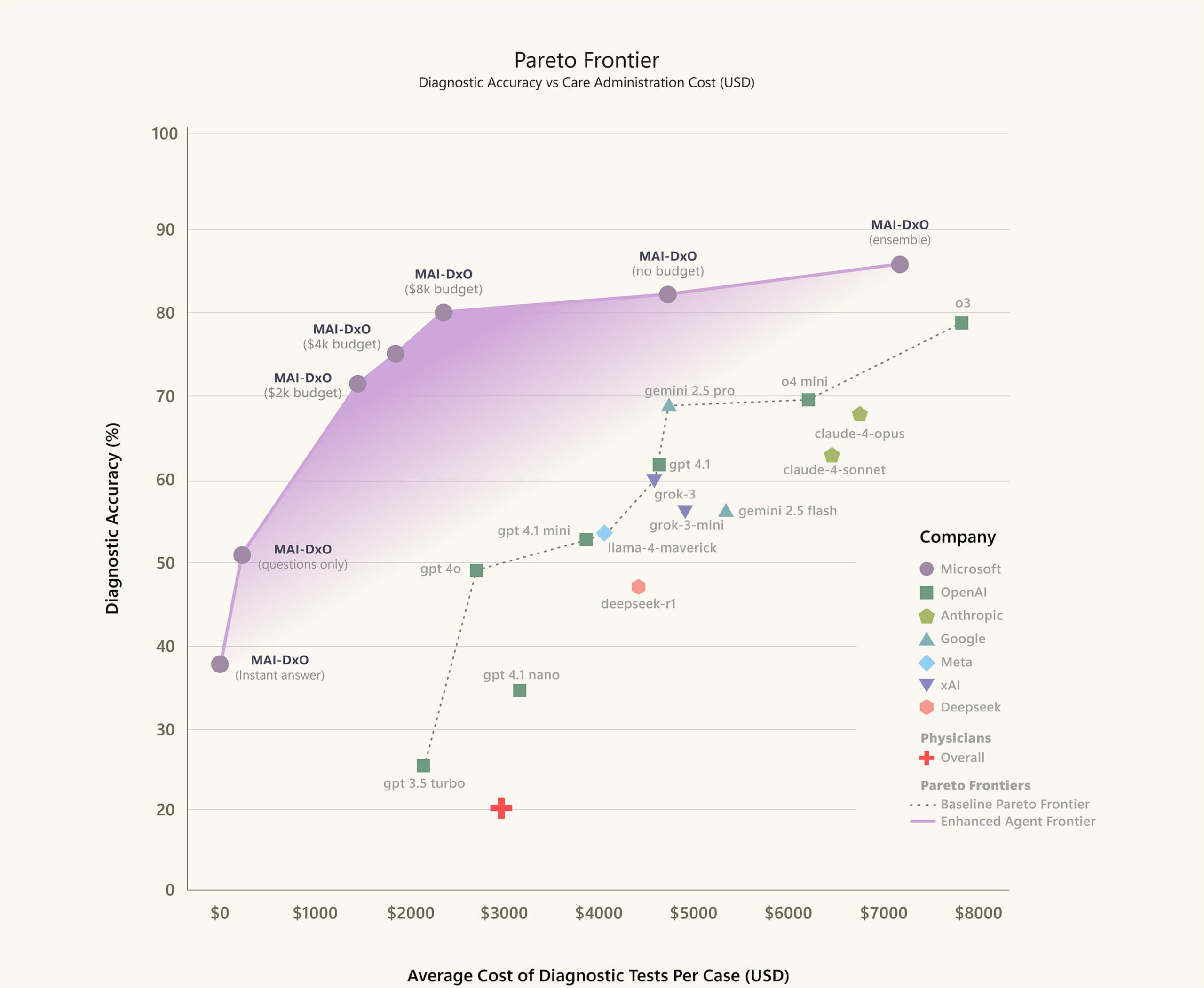
MAI-DxO aumentó el rendimiento de diagnóstico de todos los modelos que probamos. La configuración con mejor rendimiento fue MAI-DxO combinada con o3 de OpenAI, que resolvió de manera correcta el 85,5% de los casos de referencia de NEJM. A modo de comparación, también evaluamos a 21 médicos en ejercicio de los EE. UU. y el Reino Unido, cada uno con 5-20 años de experiencia clínica. En las mismas tareas, estos expertos lograron una precisión media del 20% en los casos completados.
MAI-DxO es configurable, lo que le permite operar dentro de las restricciones de costo definidas. Esto permite una exploración explícita de las compensaciones costo-valor inherentes a la toma de decisiones diagnósticas. Sin estas limitaciones, un sistema de IA podría ordenar por defecto todas las pruebas posibles, sin importar el costo, la incomodidad del paciente o los retrasos en la atención. Es importante destacar que descubrimos que MAI-DxO brindó una mayor precisión diagnóstica y menores costos generales de pruebas que los médicos o cualquier modelo de fundación individual probado.
Comparación de agentes de diagnóstico impulsados por IA por precisión y costo promedio de las pruebas de diagnóstico por caso. Los agentes con mejor rendimiento aparecen en el cuadrante superior izquierdo, lo que refleja una mayor precisión y un menor costo. La línea punteada inferior representa el rango de rendimiento de los mejores modelos de cimentación individuales. La línea púrpura traza el rendimiento de MAI-DxO en diferentes configuraciones. La cruz roja indica el rendimiento medio de 21 médicos en ejercicio.
¿Qué sigue?
Los médicos suelen caracterizarse por la amplitud o profundidad de su experiencia. Los generalistas, al igual que los médicos de familia, manejan una amplia gama de afecciones a través de las edades y los sistemas de órganos. Los especialistas, como los reumatólogos, se centran a profundidad en un solo sistema, área de enfermedad o incluso afección. Sin embargo, ningún médico por sí solo puede abarcar toda la complejidad de la serie de casos de NEJM. La IA, por otro lado, no se enfrenta a esta disyuntiva. Puede combinar la amplitud y la profundidad de la experiencia, para demostrar capacidades de razonamiento clínico que, en muchos aspectos del razonamiento clínico, superan las de cualquier médico individual.
Este tipo de razonamiento tiene el potencial de remodelar la atención médica. La IA podría empoderar a los pacientes para autogestionar los aspectos rutinarios de la atención y equipar a los médicos con apoyo avanzado para la toma de decisiones en casos complejos. Nuestros hallazgos también sugieren que la IA reduce los costos innecesarios de atención médica. El gasto sanitario de EE.UU. se acerca al 20% del PIB de EE.UU., y se estima que hasta el 25% de ese gasto se desperdicia, ya que tiene poca influencia en los resultados de los pacientes.
Por supuesto, nuestra investigación tiene importantes limitaciones. Aunque MAI-DxO sobresale en el abordaje de los desafíos de diagnóstico más complejos, se necesitan más pruebas para evaluar su rendimiento en presentaciones más comunes y cotidianas. Los médicos de nuestro estudio trabajaron sin acceso a colegas, libros de texto o incluso IA generativa, que pueden formar parte de su práctica clínica normal, para permitir una comparación justa con el rendimiento humano bruto.
Un aspecto novedoso de este trabajo es su atención al costo. Si bien los costos de salud en el mundo real varían según las zonas geográficas y los sistemas, e incluyen muchos factores posteriores que no tenemos en cuenta, aplicamos una metodología coherente en todos los agentes y médicos evaluados para ayudar a cuantificar las compensaciones de alto nivel entre la precisión del diagnóstico y el uso de recursos.
Para nosotros, este es solo el primer paso. Estamos energizados por las oportunidades que tenemos por delante. Quedan retos importantes por delante antes de que la IA generativa pueda desplegarse de forma segura y responsable en la sanidad. Necesitamos pruebas extraídas de entornos clínicos reales, junto con marcos regulatorios y de gobernanza adecuados para garantizar la fiabilidad, la seguridad y la eficacia. Es por eso que nos asociamos con organizaciones de salud líderes para probar y validar de manera rigurosa estos enfoques, un paso esencial antes de cualquier implementación más amplia.
Junto con nuestros socios, creemos con firmeza que el futuro de la atención médica se moldeará a través de aumentar la experiencia humana y la empatía con el poder de la inteligencia artificial. Estamos entusiasmados de dar los próximos pasos para hacer realidad esa visión.
—
Más información: SD Bench y MAI-DxO son solo demostraciones de investigación y en la actualidad no están disponibles como puntos de referencia públicos u orquestadores. Pueden encontrar más detalles sobre la metodología subyacente y los resultados en un artículo preimpreso publicado junto con este blog. Estamos en el proceso de presentar este trabajo para una revisión externa por pares y trabajamos de manera activa con socios para explorar el potencial de lanzar SDBench como un punto de referencia público.
Agradecimientos: Agradecemos a NEJM Group por el permiso para utilizar los casos de NEJM en la investigación reportada en esta publicación de blog. La investigación descrita aquí se ha beneficiado de las ideas de muchas personas. Agradecemos a los autores nombrados en el artículo de arXiv y al equipo más amplio de MAI. También agradecemos a otros colegas tanto dentro como fuera de Microsoft por compartir sus ideas, incluidos Bryan Bunning, Nando de Freitas, Andrija Milicevic, Hoifung Poon, David Rhew, Karén Simonyan, Eric Topol y Jim Weinstein. Gianluca Fontana y Kevin Hawkins (Prova Health) brindaron apoyo en la sección de economía y resultados de la salud.
¿Es seguro usar esta IA para la atención médica? El trabajo presentado aquí aún no está aprobado para uso clínico y solo se aprobaría después de rigurosas pruebas de seguridad, validación clínica y revisiones regulatorias. Por ahora, esto representa una investigación inicial emocionante. En el corazón de cualquier plan para implementar esta tecnología en el mundo real se encuentra nuestro compromiso con la seguridad, la confianza y la calidad, para asegurar que cualquier solución de atención médica esté fundamentada a nivel clínico, diseñada de manera ética y comunicada de manera transparente.
¿Reemplazará la IA a los médicos? Si bien la IA se ha comenzado a convertir en una herramienta poderosa en la atención médica, nuestro equipo de médicos en ejercicio cree que la IA representa un complemento para los médicos y otros profesionales de la salud. Si bien esta tecnología avanza con rapidez, sus funciones clínicas son mucho más amplias que sólo hacer un diagnóstico. Necesitan navegar por la ambigüedad y generar confianza con los pacientes y sus familias de una manera que la IA no está configurada para hacer. Creemos que las funciones clínicas evolucionarán con la IA, lo que dará a los médicos la capacidad de automatizar las tareas rutinarias, identificar enfermedades antes, personalizar los planes de tratamiento y, de manera potencial, prevenir algunas enfermedades por completo. Para los consumidores, proporcionarán mejores herramientas para la autogestión y la toma de decisiones compartida.
¿Qué es un orquestador de IA? En el contexto de la IA generativa, un orquestador es como un director digital que ayuda a coordinar múltiples pasos para lograr una tarea compleja. En el sector sanitario, el papel de la orquestación es crucial dado lo mucho que está en juego en cada decisión. Nuestro orquestador se encuentra por encima de los modelos de lenguaje subyacentes y se asegura de que cada punto para obtener un diagnóstico se maneje de manera sistemática, lo que reduce el riesgo de errores en el futuro y ofrece la estabilidad, la coherencia y la transparencia necesarias para generar confianza en los usuarios.
¿Por qué se han fijado en los costes? En un inicio, queríamos entender si la IA sólo solicitaba pruebas diagnósticas excesivas para llegar al diagnóstico correcto. Lo que descubrimos fue que nuestro orquestador fue capaz de llegar a la respuesta correcta con mucho menos dinero gastado en pruebas. En cierto modo, esto no es una sorpresa, ya que se reconoce que el exceso de pruebas diagnósticas es un desafío generalizado, lo que representa millones de pruebas innecesarias al año en los EE. UU. Este trabajo sugiere que la IA crea una oportunidad para que los médicos, y los consumidores, lleguen a un diagnóstico más rápido y preciso, al tiempo que reducen los costos.