The post Microsoft inaugura su primera Región de Datacenters en Chile para acelerar la innovación y el desarrollo económico local appeared first on Source LATAM.
Amazon S3 Express One Zone now supports renaming objects with the new RenameObject API. For the first time in S3, you can rename existing objects atomically (with a single operation) without any data movement.
The RenameObject API simplifies data management in S3 directory buckets by transforming a multi-step rename operation into a single API call. You can now rename objects in S3 Express One Zone by specifying an existing object’s name as the source and the new name of the object as the destination within the same S3 directory bucket. With no data movement involved, this capability accelerates applications like log file management, media processing, and data analytics while lowering costs. For example, renaming a 1-terabyte log file can now complete in milliseconds, instead of hours, significantly accelerating applications and reducing cost.
You can use the RenameObject API in the S3 Express One Zone storage class in all AWS Regions where the storage class is available. You can get started with the new capability in S3 Express One Zone using the AWS SDKs, AWS CLI, AWS Management Console, Amazon S3 API, or Mountpoint for Amazon S3 (version 1.19.0 or higher). To learn more, visit the S3 User Guide.
Amazon S3 Express One Zone now supports renaming objects with the new RenameObject API. For the first time in S3, you can rename existing objects atomically (with a single operation) without any data movement.
The RenameObject API simplifies data management in S3 directory buckets by transforming a multi-step rename operation into a single API call. You can now rename objects in S3 Express One Zone by specifying an existing object’s name as the source and the new name of the object as the destination within the same S3 directory bucket. With no data movement involved, this capability accelerates applications like log file management, media processing, and data analytics while lowering costs. For example, renaming a 1-terabyte log file can now complete in milliseconds, instead of hours, significantly accelerating applications and reducing cost. You can use the RenameObject API in the S3 Express One Zone storage class in all AWS Regions where the storage class is available. You can get started with the new capability in S3 Express One Zone using the AWS SDKs, AWS CLI, AWS Management Console, Amazon S3 API, or Mountpoint for Amazon S3 (version 1.19.0 or higher). To learn more, visit the S3 User Guide.
Amazon EC2 Auto Scaling now offers the ability to filter out instance details from the DescribeAutoScalingGroups API with a new parameter. With IncludeInstances set to false, you can quickly access metadata and configurations about your Auto Scaling Groups without the overhead of instance details, reducing the size of the API response and improving API response time.
The new parameter is available in all commercial AWS Regions, and AWS GovCloud (US) Regions. To learn more, see the EC2 Auto Scaling API Reference.
Amazon EC2 Auto Scaling now offers the ability to filter out instance details from the DescribeAutoScalingGroups API with a new parameter. With IncludeInstances set to false, you can quickly access metadata and configurations about your Auto Scaling Groups without the overhead of instance details, reducing the size of the API response and improving API response time. The new parameter is available in all commercial AWS Regions, and AWS GovCloud (US) Regions. To learn more, see the EC2 Auto Scaling API Reference.
AWS Parallel Computing Service (PCS) is now available in the AWS GovCloud (US-East, US-West) Regions
Today, AWS launches AWS Parallel Computing Service (PCS) in the AWS GovCloud (US-East, US-West) Regions, enabling you to easily build and manage High Performance Computing (HPC) clusters using the Slurm workload manager.
AWS PCS is a managed service that makes it easier for you to run and scale your high performance computing (HPC) workloads and build scientific and engineering models on AWS using Slurm. You can use AWS PCS to build complete, elastic environments that integrate compute, storage, networking, and visualization tools. AWS PCS simplifies cluster operations with managed updates and built-in observability features, helping to remove the burden of maintenance. You can work in a familiar environment, focusing on your research and innovation instead of worrying about infrastructure.
AWS Parallel Computing Service (PCS) is now available in the AWS GovCloud (US-East, US-West) Regions Today, AWS launches AWS Parallel Computing Service (PCS) in the AWS GovCloud (US-East, US-West) Regions, enabling you to easily build and manage High Performance Computing (HPC) clusters using the Slurm workload manager. AWS PCS is a managed service that makes it easier for you to run and scale your high performance computing (HPC) workloads and build scientific and engineering models on AWS using Slurm. You can use AWS PCS to build complete, elastic environments that integrate compute, storage, networking, and visualization tools. AWS PCS simplifies cluster operations with managed updates and built-in observability features, helping to remove the burden of maintenance. You can work in a familiar environment, focusing on your research and innovation instead of worrying about infrastructure. To get started, visit the AWS PCS page and the AWS PCS documentation.
AWS Payment Cryptography has expanded its regional presence in Asia Pacific with availability in two new regions – Asia Pacific (Mumbai) and Asia Pacific (Osaka). This expansion enables customers with latency-sensitive payment applications to build, deploy or migrate into additional AWS Regions without depending on cross-region support. For customers processing payment workloads in Asia Pacific (Tokyo), the new Osaka region offers an additional option for multi-region high availability.
AWS Payment Cryptography is a fully managed service that simplifies payment-specific cryptographic operations and key management for cloud-hosted payment applications. The service scales elastically with your business needs and is assessed as compliant with PCI PIN Security requirements, eliminating the need to maintain dedicated payment HSM instances. Organizations performing payment functions – including acquirers, payment facilitators, networks, switches, processors, and banks can now position their payment cryptographic operations closer to their cloud applications while reducing dependencies on auxiliary data centers or colocation facilities with dedicated payment HSMs.
AWS Payment Cryptography is available in the following AWS Regions: US East (Ohio, N. Virginia), US West (Oregon), Europe (Ireland, Frankfurt) and Asia Pacific (Singapore, Tokyo, Osaka, Mumbai).
To learn more about the service, see the AWS Payment Cryptography user guide, and visit the AWS Payment Cryptography page for pricing details and availability in additional regions.
AWS Payment Cryptography has expanded its regional presence in Asia Pacific with availability in two new regions – Asia Pacific (Mumbai) and Asia Pacific (Osaka). This expansion enables customers with latency-sensitive payment applications to build, deploy or migrate into additional AWS Regions without depending on cross-region support. For customers processing payment workloads in Asia Pacific (Tokyo), the new Osaka region offers an additional option for multi-region high availability. AWS Payment Cryptography is a fully managed service that simplifies payment-specific cryptographic operations and key management for cloud-hosted payment applications. The service scales elastically with your business needs and is assessed as compliant with PCI PIN Security requirements, eliminating the need to maintain dedicated payment HSM instances. Organizations performing payment functions – including acquirers, payment facilitators, networks, switches, processors, and banks can now position their payment cryptographic operations closer to their cloud applications while reducing dependencies on auxiliary data centers or colocation facilities with dedicated payment HSMs. AWS Payment Cryptography is available in the following AWS Regions: US East (Ohio, N. Virginia), US West (Oregon), Europe (Ireland, Frankfurt) and Asia Pacific (Singapore, Tokyo, Osaka, Mumbai). To learn more about the service, see the AWS Payment Cryptography user guide, and visit the AWS Payment Cryptography page for pricing details and availability in additional regions.
Starting today, Amazon Elastic Compute Cloud (Amazon EC2) C7gd instances with up to 3.8 TB of local NVMe-based SSD block-level storage are available in the Asia Pacific (Osaka, Jakarta) and South America (Sao Paulo) Regions.
These Graviton3-based instances with DDR5 memory are built on the AWS Nitro System and are a great fit for applications that need access to high-speed, low latency local storage, including those that need temporary storage of data for scratch space, temporary files, and caches. They have up to 45% improved real-time NVMe storage performance than comparable Graviton2-based instances. Graviton3-based instances also use up to 60% less energy for the same performance than comparable EC2 instances, enabling you to reduce your carbon footprint in the cloud.
Starting today, Amazon Elastic Compute Cloud (Amazon EC2) C7gd instances with up to 3.8 TB of local NVMe-based SSD block-level storage are available in the Asia Pacific (Osaka, Jakarta) and South America (Sao Paulo) Regions. These Graviton3-based instances with DDR5 memory are built on the AWS Nitro System and are a great fit for applications that need access to high-speed, low latency local storage, including those that need temporary storage of data for scratch space, temporary files, and caches. They have up to 45% improved real-time NVMe storage performance than comparable Graviton2-based instances. Graviton3-based instances also use up to 60% less energy for the same performance than comparable EC2 instances, enabling you to reduce your carbon footprint in the cloud. To learn more, see Amazon C7gd Instances. To get started, see the AWS Management Console.
Valkey announces general availability of General Language Independent Driver for the Enterprise (GLIDE) 2.0, the latest release of one of its official open source Valkey client libraries. Valkey is the most permissive open source alternative to Redis stewarded by the Linux Foundation, which means it will always be open source. Valkey GLIDE is a reliable, high-performance, multi-language client that supports all Valkey commands. GLIDE 2.0 brings new capabilities that expand developer support, improve observability, and optimize performance for high-throughput workloads.
Valkey GLIDE 2.0 extends its multi-language support to Go, joining Java, Python, and Node.js to provide a consistent, fully compatible API experience across all four languages—with more on the way. With this release, Valkey GLIDE now supports OpenTelemetry, an open source, vendor-neutral framework enabling developers to generate, collect, and export telemetry data and critical client-side performance insights. Additionally, GLIDE 2.0 introduces pipeline capabilities, reducing network overhead and latency for high-frequency use cases by allowing multiple commands to be grouped and executed as a single operation.
Valkey GLIDE is compatible with versions 7.2, 8.0 and 8.1 of Valkey, as well as versions 6.2, 7.0, and 7.2 of Redis OSS. Valkey GLIDE 2.0 is available now through the Valkey repository on GitHub. For more information about Valkey’s official client libraries, visit the Valkey website.
Valkey announces general availability of General Language Independent Driver for the Enterprise (GLIDE) 2.0, the latest release of one of its official open source Valkey client libraries. Valkey is the most permissive open source alternative to Redis stewarded by the Linux Foundation, which means it will always be open source. Valkey GLIDE is a reliable, high-performance, multi-language client that supports all Valkey commands. GLIDE 2.0 brings new capabilities that expand developer support, improve observability, and optimize performance for high-throughput workloads. Valkey GLIDE 2.0 extends its multi-language support to Go, joining Java, Python, and Node.js to provide a consistent, fully compatible API experience across all four languages—with more on the way. With this release, Valkey GLIDE now supports OpenTelemetry, an open source, vendor-neutral framework enabling developers to generate, collect, and export telemetry data and critical client-side performance insights. Additionally, GLIDE 2.0 introduces pipeline capabilities, reducing network overhead and latency for high-frequency use cases by allowing multiple commands to be grouped and executed as a single operation. Valkey GLIDE is compatible with versions 7.2, 8.0 and 8.1 of Valkey, as well as versions 6.2, 7.0, and 7.2 of Redis OSS. Valkey GLIDE 2.0 is available now through the Valkey repository on GitHub. For more information about Valkey’s official client libraries, visit the Valkey website.
Desarrollo de la gestión de la atención oncológica de última generación con orquestación multiagente
Por: Matthew Lungren, MD, MPH, director científico de ciencias de la salud y de la vida.
Cada año, 20 millones de personas en todo el mundo son diagnosticadas con cáncer.1 Cada paciente es único, con cientos de subtipos de tumores distintos, cada uno de los cuales exige protocolos de tratamiento que incluyen nuevos fármacos, combinaciones, ensayos clínicos y terapias basadas en dispositivos. Los principales centros oncológicos dependen en gran medida de las juntas multidisciplinarias de tumores, sesiones dedicadas en las que radiólogos, patólogos, cirujanos, oncólogos, asesores genéticos y otros especialistas realizan análisis sofisticados de una gran cantidad de datos y conocimientos de los pacientes para alinearse con los planes de atención personalizados.
Debido a la inmensa preparación y especialización requeridas, menos del 1% de estos pacientes tienen acceso a estos planes de tratamiento personalizados, que han mejorado, con pruebas demostrables, los resultados de los pacientes.
Un estudio reciente de la Sociedad Americana de Oncología Clínica (American Society of Clinical Oncology, ASCO) destacó que los médicos pasan entre 1,5 y 2,5 horas por paciente, en revisar de manera meticulosa las imágenes, las láminas de patología, las notas clínicas y los datos genómicos.2 Y la atención oncológica es solo un ejemplo del complejo análisis de datos que requiere la atención médica. La IA agéntica tiene el potencial de reducir la fricción administrativa y transformar aún más la prestación de atención.
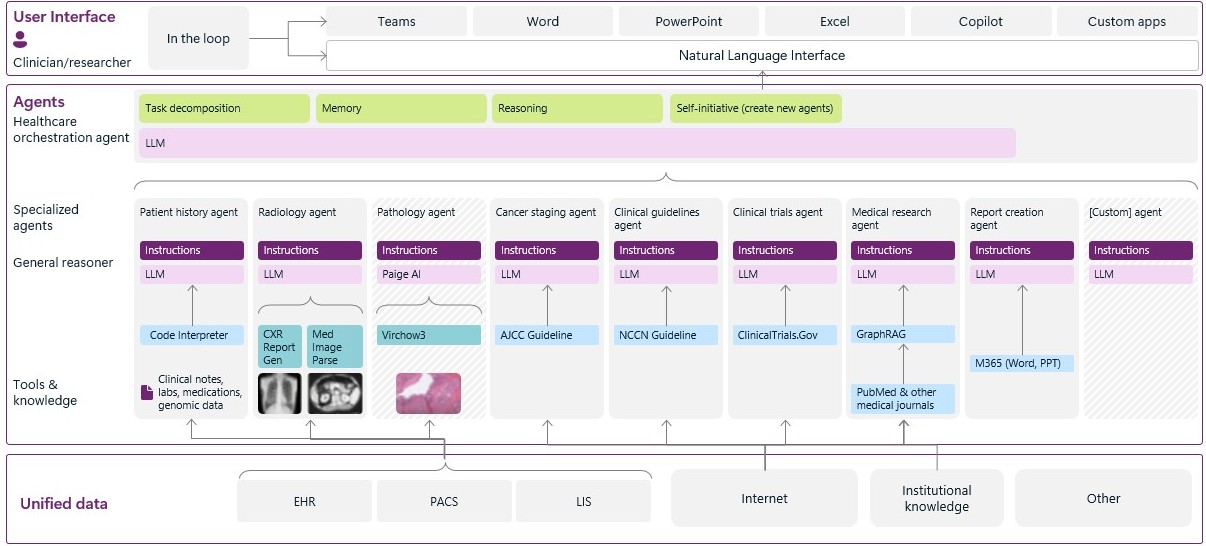
El orquestador de agentes del cuidado de la salud ya está disponible en el catálogo de agentes de Azure AI Foundry. Cuenta con agentes preconfigurados con orquestación multiagente y opciones de personalización de código abierto que permiten a los desarrolladores e investigadores crear agentes que coordinen flujos de trabajo de datos de atención médica multidisciplinarios y multimodales, como juntas de tumores, y optimicen la implementación en herramientas de productividad empresarial de atención médica (como Microsoft Teams y Word). Los razonadores generales modulares, así como los agentes de IA especializados y multimodales, trabajan juntos para abordar tareas que llevarían horas, con el objetivo de aumentar de manera eficaz a los especialistas clínicos con IA agéntica de vanguardia personalizada.
Al integrar las capacidades más recientes de Microsoft, el orquestador de agentes de atención médica puede administrar el análisis y el razonamiento sobre diversos tipos de datos de atención médica, que van desde imágenes (archivos DICOM) y patología (imágenes de portaobjetos completos) hasta datos genómicos y notas clínicas de registros de salud electrónicos (EHR, por sus siglas en inglés). Cada agente está equipado con modelos de IA avanzados de Azure AI Foundry, que combinan capacidades de razonamiento de uso general con modelos de modalidad específicos de la atención médica para generar información procesable basada en datos clínicos multimodales.
Capacidades clave del orquestador de agentes sanitarios
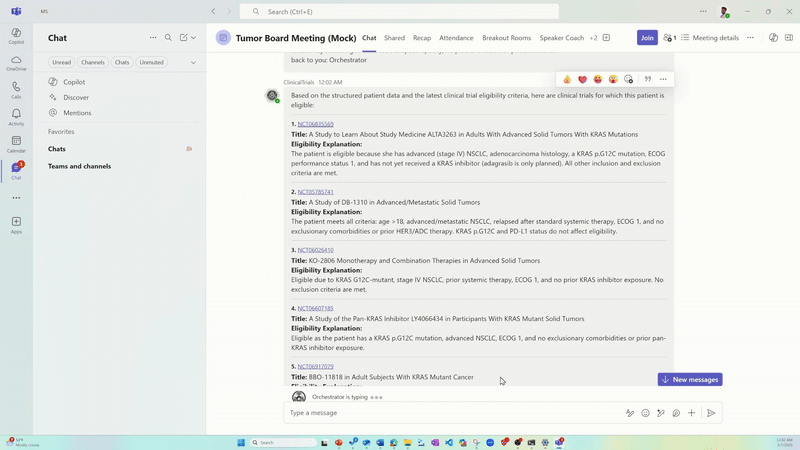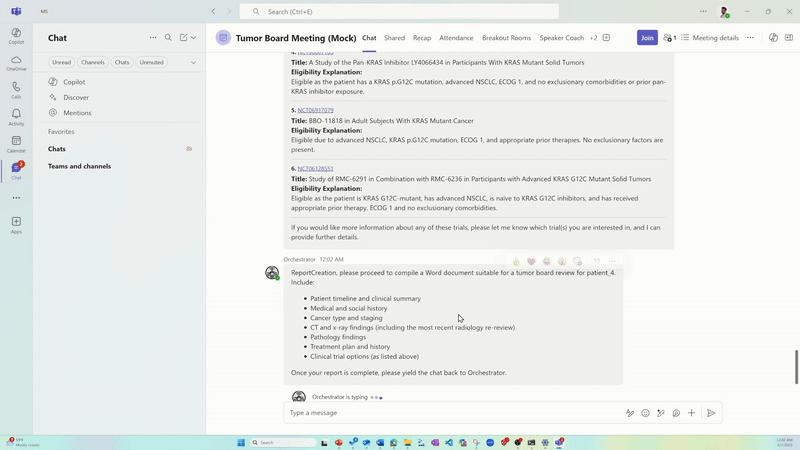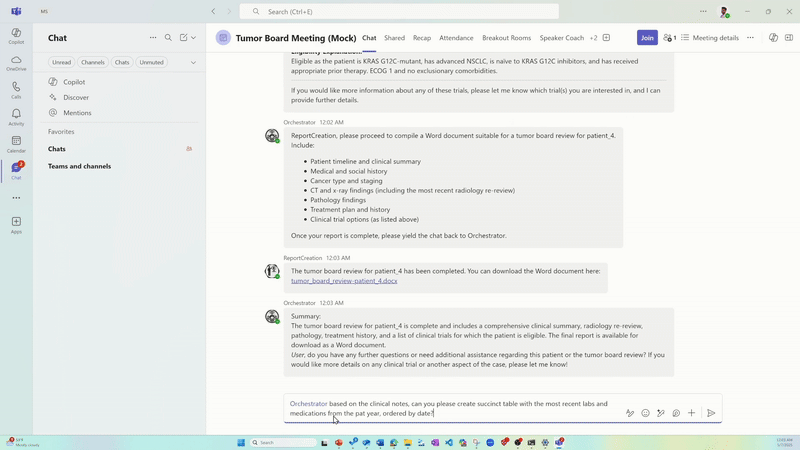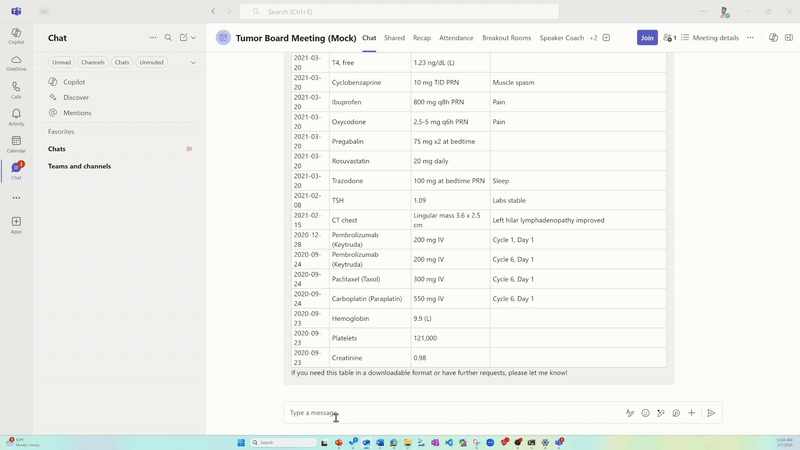
Orquestar capacidades de agentes que puedan razonar sobre datos complejos de EHR y aumentar las tareas que consumen mucho tiempo, como la creación de una línea de tiempo cronológica del paciente, la determinación del estadio del cáncer, el uso de pautas de referencia específicas, la revisión de imágenes de radiología y patología, la síntesis de la literatura médica actual, la referencia de las pautas de tratamiento, la aparición de ensayos clínicos relevantes y la generación de informes personalizados.
Proporcionar herramientas que conecten los datos de atención médica de la empresa a través de Microsoft Fabric y el servicio de datos de recursos de interoperabilidad de atención médica (FHIR, por sus siglas en inglés) rápido.
Garantizar la interoperabilidad y la integración en los flujos de trabajo existentes, incluida la distribución a herramientas conocidas que ya utilizan la mayoría de las organizaciones sanitarias (Teams, Word, PowerPoint y Microsoft 365 Copilot), donde los usuarios pueden interactuar con los agentes de IA.
Proporcionar sólidas capacidades de explicabilidad en los resultados generados por la IA de los agentes, como las respuestas de conexión a tierra a los datos de EHR de origen, lo que es fundamental para la validación, la confianza y la adopción en entornos sanitarios de alto riesgo.
Los investigadores y desarrolladores de las principales instituciones de atención oncológica, como la Universidad de Stanford, Johns Hopkins, Providence Genomics, Mass General Brigham y la Facultad de Medicina y Salud Pública de la Universidad de Wisconsin, en la actualidad exploran el orquestador de agentes sanitarios para estudiar cómo la IA agéntica podría aportar valor a tareas clínicas complejas, como la atención del cáncer.
«Stanford Medicine atiende a 4.000 pacientes al año con la junta de tumores, y nuestros médicos ya utilizan resúmenes generados por el modelo de fundación en las reuniones de la junta de tumores hoy en día (a través de una instancia segura de PHI de GPT en Azure). El nuevo orquestador de agentes sanitarios tiene el poder de optimizar este flujo de trabajo existente al reducir la fragmentación (al ahorrar tiempo al evitar copiar y pegar) y permite sacar a la luz nuevos conocimientos a partir de elementos de datos que eran difíciles de buscar, como los criterios de elegibilidad de los ensayos, las pautas de tratamiento y las pruebas del mundo real. Stanford Health Care está entusiasmado con la investigación adicional del potencial de usar el orquestador de agentes de atención médica para construir la primera solución de agente de IA generativa utilizada en un entorno de producción para la atención en el mundo real para nuestros pacientes con cáncer«. —Dr. Mike Pfeffer, director de información, Stanford Health Care y Escuela de Medicina de Stanford
«La visión del orquestador de agentes de atención médica es sacar, resumir y tomar medidas de manera rápida sobre la información médica multimodal relevante para cada caso complejo de cáncer, de modo que las horas de revisión se conviertan en minutos. La colaboración con Microsoft nos permite explorar el valor de estos modelos para las placas de tumores y más allá». —Dr. Joshua Warner, radiólogo de UW Health y profesor asistente de radiología de la Facultad de Medicina y Salud Pública de UW
Las primeras colaboraciones de desarrollo incluyeron la integración de este flujo de trabajo multiagente en los chats de Teams, donde, por ejemplo, los chats grupales permitían conversaciones entre varios expertos humanos y agentes especializados en IA sanitaria conectados a datos sanitarios específicos. Demostró la promesa de mejorar de manera significativa la eficiencia y la colaboración entre los proveedores clínicos. Esta capacidad ya reúne a médicos y desarrolladores para crear las aplicaciones de atención médica agentica del futuro: el catalizador es la poderosa combinación de agentes específicos de atención médica que utilizan modelos de razonamiento general y modelos de base de atención médica multimodal junto con la capacidad de interactuar de manera directa con agentes personalizados mediante Teams.
Por ejemplo, los oncólogos de Johns Hopkins, el Dr. Vasan Yegnasubramanian, la Dra. Elsa Anagnostou y el Dr. Taxiarchis Botsis, y sus equipos de desarrollo en el programa de Medicina de Precisión inHealth de Johns Hopkins y la Junta de Tumores Moleculares aportan su experiencia para refinar y probar el sistema para garantizar que tenga una gran utilidad si se utiliza en sus aplicaciones clínicas y de medicina de precisión.
Coordinación de la colaboración de agentes especializados
El orquestador de agentes sanitarios se basa en investigaciones y versiones recientes de Microsoft Research y nuestros colaboradores. Coordina la colaboración de agentes especializados diseñados de manera explícita para flujos de trabajo clínicos multidisciplinarios complejos, como la atención del cáncer.
El orquestador aprovecha Kernel semántico y Magentic-One para coordinar agentes, mantener la memoria compartida e interactuar con el humano en el bucle.
El agente de historial del paciente aprovecha la abstracción médica universal para organizar los datos del paciente cronológicamente.3 El trabajo manual que puede llevar a los expertos más de tres horas ocurre en minutos.
El agente de radiología aprovecha los modelos ajustados por el cliente, como CXRRepotGen/MAIRA-2, para analizar las imágenes radiológicas para una segunda lectura.4
El agente de patología demuestra cómo conectarse a agentes externos como el agente de patología «Alba» de Paige.ai para abordar consultas complejas relacionadas con las imágenes de patología (disponible en versión preliminar).5
El agente de estadificación del cáncer se refiere a las pautas clínicas del American Joint Committee on Cancer (AJCC) para respaldar la estadificación precisa del cáncer.
El agente de guías clínicas hace referencia a las guías clínicas de la National Comprehensive Cancer Network (NCCN) para sugerir planes de tratamiento recomendados.
El agente de ensayos clínicos identifica los ensayos clínicos elegibles al hacer coincidir los perfiles de los pacientes con bases de datos como ClinicalTrials.gov. Esto puede resultar en más del doble de la mejora de la recuperación en comparación con la línea de base Critera2Query disponible de manera pública.6
El agente de investigación médica ofrece orientación práctica y basada en la evidencia basada en el conocimiento basado en gráficos de revistas médicas confiables.
El agente de creación de informes automatiza los informes completos, integrados y con un formato enriquecido que sirven como referencia de confianza durante las reuniones multidisciplinarias.
«A medida que avanzamos hacia el uso rutinario de sistemas multiagente, el orquestador de agentes sanitarios demuestra el poder de simplificar la integración de varios modelos y agentes con herramientas de productividad que los médicos ya están utilizando. El marco de orquestación flexible facilitará que en Paige sigamos centrándonos en nuestros agentes patológicos, al tiempo que permite su integración en el flujo de trabajo más amplio de la atención oncológica y aprovecha el acceso a los datos multimodales». —Razik Yousfi, director ejecutivo de Paige.ai
El orquestador es abierto de manera intencionada: cualquier agente aprobado, incluido un tercero, que exponga una API, un contenedor de herramientas o un punto de conexión de MCP se puede extraer en un subproceso conversacional de Teams. Paige.ai envía su agente Alba en versión preliminar, el primer ejemplo de un agente externo que se puede conectar al orquestador de agentes de atención médica. Construido sobre los modelos de visión a escala de base de Paige y junto con un front-end de modelo de lenguaje conversacional (LLM, por sus siglas en inglés), Alba ofrece información sobre patología digital conversacional en tiempo real, como el grado del tumor, la morfología y el estado de los biomarcadores, directo a partir de imágenes de diapositivas completas.
«Los investigadores clínicos de Providence han comenzado a aprovechar las capacidades avanzadas de IA proporcionadas por el orquestador de agentes de atención médica para analizar de manera rápida y eficiente grandes conjuntos de publicaciones, ensayos clínicos y registros de salud electrónicos. Estamos entusiasmados con su potencial para mejorar nuestra capacidad de interpretar la genómica y hacer coincidir los ensayos clínicos en las juntas de tumores moleculares, lo que en última instancia beneficia la atención al paciente al proporcionar opciones de tratamiento más precisas y oportunas. Su integración en nuestros flujos de trabajo también ayudará a agilizar la comunicación y la colaboración entre los proveedores clínicos, lo que asegura que la información clínica crítica se comparta con prontitud y precisión. A medida que continuamos la exploración de nuevas formas de comprender la biología del cáncer, sus capacidades serán fundamentales para impulsar los descubrimientos médicos y avanzar en el tratamiento del cáncer». —Carlo Bifulco, MD, director médico de Providence Genomics y profesor de investigación en el Instituto de Investigación Earle A. Chiles
Capacitar a los desarrolladores para acelerar las innovaciones de los equipos de atención
A medida que aumenta la complejidad de la atención clínica, el orquestador de agentes sanitarios permite a los desarrolladores navegar con confianza por la era acelerada de la IA agentica, colaborar con los médicos y democratizar las herramientas de medicina de precisión al incorporar estas capacidades a los flujos de trabajo existentes. El marco inicial está diseñado para estudiar la oportunidad de ayudar a las juntas de tumores. La visión final es capacitar a los desarrolladores de atención médica y ciencias de la vida para investigar cómo las capacidades de IA agéntica podrían afectar a los médicos y pacientes en general al brindar soporte en tiempo real a los equipos de atención multidisciplinarios en todo el ecosistema de atención médica.
Se invita a los desarrolladores de atención médica y a las organizaciones clínicas a explorar el orquestador de agentes de atención médica, disponible a través del catálogo de agentes de Azure AI Foundry. Interactúen con la próxima generación de agentes sanitarios impulsados por IA hoy mismo.
El orquestador de agentes sanitarios está diseñado para su uso en investigación y desarrollo. No está diseñado ni destinado a ser implementado en entornos clínicos tal cual ni está destinado a su uso en el diagnóstico o tratamiento de ninguna afección médica o de salud, y no se ha establecido su rendimiento para tales fines. Ustedes son los únicos responsables de cualquier uso del orquestador de agentes sanitarios, incluida la verificación de los resultados y la incorporación a cualquier producto o servicio destinado a un fin médico o para informar sobre la toma de decisiones clínicas, el cumplimiento de las leyes y normativas sanitarias aplicables y la obtención de las autorizaciones o aprobaciones necesarias.
Starting today, you can use AWS Lambda SnapStart for your Python and .NET functions in 23 additional AWS Regions. Lambda SnapStart is an opt-in capability that delivers faster startup performance, from several seconds to as low as sub-second. SnapStart makes it easier for you to build highly responsive and scalable applications without provisioning resources or implementing complex performance optimizations.
For latency sensitive applications that support unpredictable bursts of traffic, high startup latencies—known as cold starts—can cause delays in your users’ experience. Lambda SnapStart can improve startup times by initializing the function’s code ahead of time, taking a snapshot of the initialized execution environment, and caching it. When the function is invoked and subsequently scales up, Lambda SnapStart resumes new execution environments from the cached snapshot instead of initializing them from scratch, significantly improving startup latency. Lambda SnapStart is ideal for applications such as synchronous APIs, interactive microservices, data processing, and ML inference.
With today’s launch, you can use AWS Lambda SnapStart for Python and .NET in 23 additional AWS Regions: Africa (Cape Town), Asia Pacific (Hong Kong, Seoul, Osaka, Mumbai, Jakarta, Hyderabad, Melbourne, Malaysia, Thailand), Canada (Central, West), Europe (Zurich, Milan, Spain, London, Paris), Israel (Tel Aviv), Middle East (UAE, Bahrain), Mexico (Central), South America (Sao Paulo), and US West (N. California).
You can activate SnapStart for new or existing Lambda functions running on Python 3.12 (and newer) and .NET 8 (and newer) using the AWS Lambda API, AWS Management Console, AWS Command Line Interface (AWS CLI), AWS Cloud Formation, AWS Serverless Application Model (AWS SAM), AWS SDK, and AWS Cloud Development Kit (AWS CDK). For more information, see the Lambda SnapStart documentation, or the launch blog post. To learn more about pricing for SnapStart on Python and .NET, visit AWS Lambda Pricing.
Starting today, you can use AWS Lambda SnapStart for your Python and .NET functions in 23 additional AWS Regions. Lambda SnapStart is an opt-in capability that delivers faster startup performance, from several seconds to as low as sub-second. SnapStart makes it easier for you to build highly responsive and scalable applications without provisioning resources or implementing complex performance optimizations. For latency sensitive applications that support unpredictable bursts of traffic, high startup latencies—known as cold starts—can cause delays in your users’ experience. Lambda SnapStart can improve startup times by initializing the function’s code ahead of time, taking a snapshot of the initialized execution environment, and caching it. When the function is invoked and subsequently scales up, Lambda SnapStart resumes new execution environments from the cached snapshot instead of initializing them from scratch, significantly improving startup latency. Lambda SnapStart is ideal for applications such as synchronous APIs, interactive microservices, data processing, and ML inference. With today’s launch, you can use AWS Lambda SnapStart for Python and .NET in 23 additional AWS Regions: Africa (Cape Town), Asia Pacific (Hong Kong, Seoul, Osaka, Mumbai, Jakarta, Hyderabad, Melbourne, Malaysia, Thailand), Canada (Central, West), Europe (Zurich, Milan, Spain, London, Paris), Israel (Tel Aviv), Middle East (UAE, Bahrain), Mexico (Central), South America (Sao Paulo), and US West (N. California). You can activate SnapStart for new or existing Lambda functions running on Python 3.12 (and newer) and .NET 8 (and newer) using the AWS Lambda API, AWS Management Console, AWS Command Line Interface (AWS CLI), AWS Cloud Formation, AWS Serverless Application Model (AWS SAM), AWS SDK, and AWS Cloud Development Kit (AWS CDK). For more information, see the Lambda SnapStart documentation, or the launch blog post. To learn more about pricing for SnapStart on Python and .NET, visit AWS Lambda Pricing.
Starting today, Amazon Elastic Compute Cloud (Amazon EC2) M7g instances are available in the AWS Africa (Cape Town) and AWS Asia Pacific (Hong Kong) regions. These instances are powered by AWS Graviton3 processors that provide up to 25% better compute performance compared to AWS Graviton2 processors, and built on top of the the AWS Nitro System, a collection of AWS designed innovations that deliver efficient, flexible, and secure cloud services with isolated multi-tenancy, private networking, and fast local storage.
Amazon EC2 Graviton3 instances also use up to 60% less energy to reduce your cloud carbon footprint for the same performance than comparable EC2 instances. For increased scalability, these instances are available in 9 different instance sizes, including bare metal, and offer up to 30 Gbps networking bandwidth and up to 20 Gbps of bandwidth to the Amazon Elastic Block Store (EBS).
Starting today, Amazon Elastic Compute Cloud (Amazon EC2) M7g instances are available in the AWS Africa (Cape Town) and AWS Asia Pacific (Hong Kong) regions. These instances are powered by AWS Graviton3 processors that provide up to 25% better compute performance compared to AWS Graviton2 processors, and built on top of the the AWS Nitro System, a collection of AWS designed innovations that deliver efficient, flexible, and secure cloud services with isolated multi-tenancy, private networking, and fast local storage. Amazon EC2 Graviton3 instances also use up to 60% less energy to reduce your cloud carbon footprint for the same performance than comparable EC2 instances. For increased scalability, these instances are available in 9 different instance sizes, including bare metal, and offer up to 30 Gbps networking bandwidth and up to 20 Gbps of bandwidth to the Amazon Elastic Block Store (EBS). To learn more, see Amazon EC2 M7g. To explore how to migrate your workloads to Graviton-based instances, see AWS Graviton Fast Start program and Porting Advisor for Graviton. To get started, see the AWS Management Console.